[15]:
import logging
import warnings
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
import SpectralToolbox.Spectral1D as S1D
import TransportMaps as TM
import TransportMaps.Maps.Functionals as FUNC
import TransportMaps.Maps as MAPS
from TransportMaps import KL
warnings.simplefilter("ignore")
TM.setLogLevel(logging.INFO)
Available approximations¶
Let us consider the random variable \(X\) distributed accordingly to the Gumbel distribution, with density
where \(z=\frac{x-\mu}{\beta}\). Given the standard normal reference density \(\rho\), we are looking for the map \(T:\mathbb{R}\rightarrow \mathbb{R}\) such that
We measure the quality of such approximation using the Kullback-Leibler divergence, and thus we try to solve the following minimization problem
over a set \(\mathcal{T}_\triangle\) of triangular and monotonic transport maps. Elements of this set are parametrized and denoted by \(T({\bf a},\cdot)\).
First of all we need to define the distribution \(\nu_\pi\), its density and a couple of its derivaties. This is done by the extension of the class Distribution.
[3]:
import TransportMaps.Distributions as DIST
class GumbelDistribution(DIST.Distribution):
def __init__(self, mu, beta):
super(GumbelDistribution,self).__init__(1)
self.mu = mu
self.beta = beta
self.dist = stats.gumbel_r(loc=mu, scale=beta)
def pdf(self, x, params=None, *args, **kwargs):
return self.dist.pdf(x).flatten()
def log_pdf(self, x, params=None, *args, **kwargs):
return self.dist.logpdf(x).flatten()
def grad_x_log_pdf(self, x, params=None, *args, **kwargs):
m = self.mu
b = self.beta
z = (x-m)/b
return (np.exp(-z)-1.)/b
def hess_x_log_pdf(self, x, params=None, *args, **kwargs):
m = self.mu
b = self.beta
z = (x-m)/b
return (-np.exp(-z)/b**2.)[:,:,np.newaxis]
mu = 3.
beta = 4.
pi = GumbelDistribution(mu,beta)
The code above defines the gradient and the Hessian of the log-pdf of the target. The availability of such information helps the optimizer finding the solution, but it is not necessary in general. In absence of such the Hessian and gradient information, one can use derivative free methods to solve the minimization problem. The TransportMaps framework can switch between the available methods depending on the problem formulation.
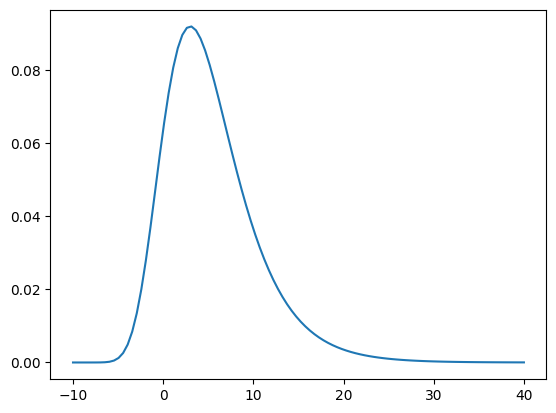
Let’s see how the PDF of the defined Gumbel density looks like.
[4]:
x = np.linspace(-10., 40., 100).reshape((100,1))
plt.figure()
plt.plot(x, pi.pdf(x));
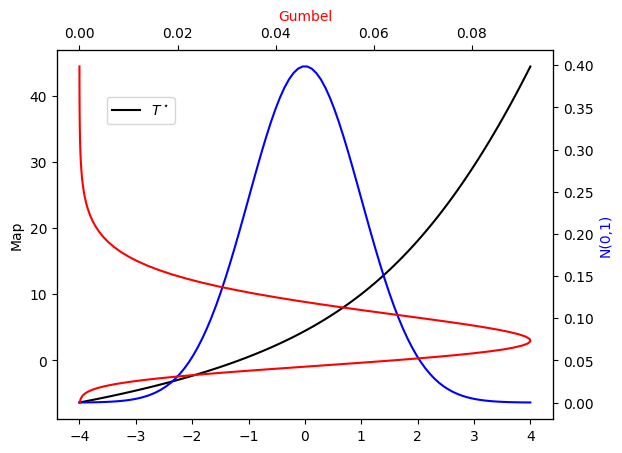
For the sake of exposition we will provide here also a function that computes the exact transport \(T^\star\) between a Standard Normal distribution \(\nu_\rho\) and the target Gumbel distribution \(\nu_\pi\)
[5]:
class GumbelTransportMap(object):
def __init__(self, mu, beta):
self.tar = stats.gumbel_r(loc=mu, scale=beta)
self.ref = stats.norm(0.,1.)
def evaluate(self, x, params=None):
if isinstance(x,float):
x = np.array([[x]])
if x.ndim == 1:
x = x[:,NAX]
out = self.tar.ppf( self.ref.cdf(x) )
return out
def __call__(self, x):
return self.evaluate(x)
Tstar = GumbelTransportMap(mu,beta)
Let’s see how the exact transport map \(T^\star\) looks like.
[6]:
x_tm = np.linspace(-4,4,100).reshape((100,1))
def plot_mapping(tar_star, Tstar, tar=None, T=None):
fig = plt.figure()
ax = fig.add_subplot(111)
ax_twx = ax.twinx()
ax_twy = ax.twiny()
ax.plot(x_tm, Tstar(x_tm), 'k-', label=r"$T^\star$") # Map
n01, = ax_twx.plot(x_tm, stats.norm(0.,1.).pdf(x_tm), '-b') # N(0,1)
g, = ax_twy.plot(tar_star.pdf(Tstar(x_tm)), Tstar(x_tm), '-r') # Gumbel
if T is not None:
ax.plot(x_tm, T(x_tm), 'k--', label=r"$\hat{T}$") # Map
if tar is not None:
ax_twy.plot(tar.pdf(Tstar(x_tm)), Tstar(x_tm), '--r') # Gumbel
ax.set_ylabel(r"Map")
ax_twx.set_ylabel('N(0,1)')
ax_twx.yaxis.label.set_color(n01.get_color())
ax_twy.set_xlabel('Gumbel')
ax_twy.xaxis.label.set_color(g.get_color())
ax.legend(loc = (0.1, 0.8))
[7]:
plot_mapping(pi, Tstar)
The triangular transport map \(T\), in the \(d\) dimensional case, takes the form:
In the case we are describing \(d=1\), then \(T({\bf a};{\bf x}) = T_1({\bf a}_1;x_1)\).
We can chose between several types of parametrizations for \(T_1,\ldots,T_d\): the linear span parametrization, the integrated exponential parametrization and the integrated squared parametrization. For robustness we recommend to use either the integrated exponential parametrization or the integrated squared parametrization
Laplace approximation¶
The Laplace approximation consists in the fit of a Gaussian distribution \(\tilde{\pi} \sim \mathcal{N}(\mu, \Sigma)\) to the target \(\pi\), where we select the mean to be (one of) the mode(s) of the distribution
and \(\Sigma^{-1} = -\nabla^2 \log \pi(\mu)\). Then the linear transport map that pushes forward the reference distribution \(\rho \sim \mathcal{N}({\bf 0},{\bf I})\) to the approximation \(\tilde{\pi}\) of \(\pi\) (\(L_{\sharp} \rho = \tilde{\pi} \approx \pi\)) is given by
[8]:
laplace_approx = TM.laplace_approximation(pi)
L = MAPS.LinearTransportMap.build_from_Gaussian(laplace_approx)
rho = DIST.StandardNormalDistribution(1)
approx_pi = DIST.PushForwardTransportMapDistribution(L, rho)
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Obj. Eval. 1 - f val. = 2.7532943777e+00
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Grad. Obj. Eval. 1 - ||grad f|| = 2.7925000415e-01
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Hess. Obj. Eval. 1
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Obj. Eval. 2 - f val. = 2.4129569374e+00
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Grad. Obj. Eval. 2 - ||grad f|| = 6.2257282254e-02
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Hess. Obj. Eval. 2
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Obj. Eval. 3 - f val. = 2.3865606307e+00
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Grad. Obj. Eval. 3 - ||grad f|| = 5.8136656795e-03
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Hess. Obj. Eval. 3
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Obj. Eval. 4 - f val. = 2.3862943955e+00
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Grad. Obj. Eval. 4 - ||grad f|| = 6.5563577720e-05
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Hess. Obj. Eval. 4
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Obj. Eval. 5 - f val. = 2.3862943611e+00
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Grad. Obj. Eval. 5 - ||grad f|| = 8.5941603278e-09
2023-03-25 23:55:52 INFO: TransportMaps: Lap. Hess. Obj. Eval. 5
2023-03-25 23:55:52 INFO: TransportMaps: Optimization terminated successfully
2023-03-25 23:55:52 INFO: TransportMaps: Function value: 2.386294
2023-03-25 23:55:52 INFO: TransportMaps: Jacobian: 2-norm: 8.594160e-09 inf-norm: 8.594160e-09
2023-03-25 23:55:52 INFO: TransportMaps: Number of iterations: 5
2023-03-25 23:55:52 INFO: TransportMaps: N. function evaluations: 5
2023-03-25 23:55:52 INFO: TransportMaps: N. Jacobian evaluations: 5
2023-03-25 23:55:52 INFO: TransportMaps: N. Hessian evaluations: 5
2023-03-25 23:55:52 WARNING: TransportMaps: build_from_Gaussian DEPRECATED since v3.0. Use build_from_Normal instead
2023-03-25 23:55:52 WARNING: TransportMaps: sigma DEPRECATED since v3.0. Use property covariance instead.
2023-03-25 23:55:52 WARNING: TransportMaps: LinearTransportMap DEPRECATED since v3.0. Use Maps.AffineTransportMap instead
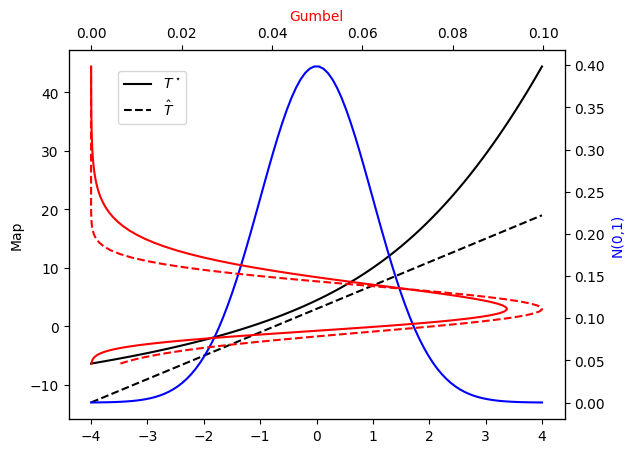
Let’s check the PDF approximation against the exact Gumbel distribution…
[9]:
plot_mapping(pi, Tstar, approx_pi, L)
Linear span parametrization¶
The linear span parametrization takes the simple form:
A 3-rd order polynomial approximation can be built using the following code:
[10]:
order = 3
Tk_list = []
active_vars = []
basis_list = [ S1D.HermiteProbabilistsPolynomial() ]
order_list = [ order ]
Tk = FUNC.MonotonicLinearSpanApproximation(
basis_list, spantype='full', order_list=order_list)
Tk_list.append( Tk )
active_vars.append( [0] )
T = MAPS.MonotonicLinearSpanTriangularTransportMap(active_vars, Tk_list)
2023-03-25 23:55:59 WARNING: TransportMaps: MonotonicLinearSpanApproximation DEPRECATED since v3.0. Use Functionals.PointwiseMonotoneLinearSpanTensorizedParametricFunctional instead.
2023-03-25 23:55:59 WARNING: TransportMaps: MonotonicLinearSpanTriangularTransportMap DEPRECATED since v3.0. Use Maps.NonMonotoneLinearSpanParametricTriangularComponentwiseTransportMap instead.
In the code above
basis_listcontains a list of one dimensional basis. Since \(d=1\) the list contains only one element.orders_list, which define the polynomial order for in each dimension.Tkis the approximation \(T_1\) defined above.The approximations \(T_1,\ldots,T_d\) are collected into the list
Tk_list.Element
iofapprox_varsstates which are the active variables for approximation \(T_i\). In this \(T_1\) depends only on \(x_1\) (in python counting, variable0).Trepresents the map \(T\).
Alternatively, one can use the default constructor:
[13]:
T = MAPS.assemble_IsotropicLinearSpanTriangularTransportMap(
1, order, 'full')
2023-03-25 23:56:29 WARNING: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: Be advised that in the current implementation of the "CommonBasis" componentwise maps, max_orders does not get updated when underlying directional orders change!!! (e.g. adaptivity)
We are then ready to set up the minimization problem
where \(\rho\) is a chosen reference distribution (Standard Normal).
Recall that the set \(\mathcal{T}_\triangle\) contains all the lower triangular maps monotonic in their last variable. Unfortunately when we restric our attention to the set \(\mathcal{P}_\triangle\), the lower triangular polynomial maps, the approximation is not monotonic in general. Monotonicity needs to be enforced. This is done locally at the sampling points used to approximate the KL-divergence. To see how this is done, we need to explain how the optimization problem is actually formulated.
Note that
where the last term is the entropy of \(\rho\) and does not depend on the transport map.
The expectation \(\mathbb{E}_{\rho}\) will be in general approximated using quadratures \(\{{\bf x}_i,w_i\}_{i=1}^M\), leading to the optimization problem
Focusing on lower triangular polynomial approximations \(\mathcal{P}_\triangle\), we obtain the following constrained optimization problem:
All these details are accounted for inside the TransportMaps implementation, which will detect the need to reformulate the problem accordingly when it encounters lower triangular polynomial approximations.
The only thing the user need to do is to chose a reference distribution \(\nu_\rho\) (Standard normal) and to construct the distribution \(T_\sharp \nu_\rho\):
[14]:
rho = DIST.StandardNormalDistribution(1)
push_rho = DIST.PushForwardParametricTransportMapDistribution(T, rho)
pull_pi = DIST.PullBackParametricTransportMapDistribution(T, pi)
We are then ready to solve the optimization problem in the original form:
[16]:
qtype = 3 # Gauss quadrature
qparams = [20] # Quadrature order
reg = None # No regularization
tol = 1e-10 # Optimization tolerance
ders = 1 # Use gradient
log = KL.minimize_kl_divergence(
rho, pull_pi, qtype=qtype, qparams=qparams, regularization=reg,
tol=tol, ders=ders)
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: Gradient norm tolerance set to 1e-10
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: Starting BFGS with user provided Jacobian
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: Iteration 1 - obj = 2.61510e+00 - jac 2-norm = 4.49e-01 - jac inf-norm = 4.09e-01
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: Iteration 2 - obj = 2.31146e+00 - jac 2-norm = 2.87e-01 - jac inf-norm = 2.22e-01
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: Iteration 3 - obj = 2.01363e+00 - jac 2-norm = 1.90e-01 - jac inf-norm = 1.74e-01
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: Iteration 4 - obj = nan - jac 2-norm = 1.90e-01 - jac inf-norm = 1.65e-01
2023-03-25 23:57:17 WARNING: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Minimization of KL-divergence failed.
2023-03-25 23:57:17 WARNING: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Message: Desired error not necessarily achieved due to precision loss.
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Function value: nan
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Jacobian 2-norm: 1.900979e-01 inf-norm: 1.650107e-01
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Number of iterations: 4
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. function evaluations: 14
2023-03-25 23:57:17 INFO: TM.NonMonotoneCommonBasisLinearSpanParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. Jacobian evaluations: 14
One could also solve the problem without using gradient information (e.g., if not available). The optimizer would in this case resort to gradient free solvers.
Let’s check the PDF approximation against the exact Gumbel distribution and the corresponding maps…
[17]:
plot_mapping(pi, Tstar, push_rho, T)
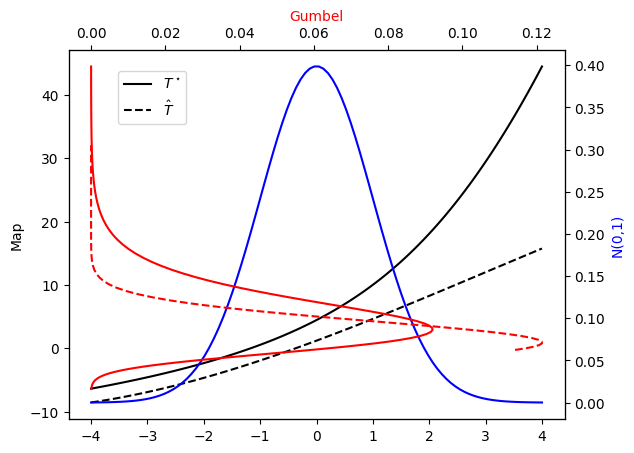
Integrated exponential parametrization¶
This parameterization takes the form:
where \(c\) and \(h\) are themselves two parametric approximations. We use polynomial approximations for both of these functions, such that:
In general we will require the approximation \(c\) to be constant in \(x_d\) and this is achieved using a zero’s order approximation in the \(x_d\) dimension of \(c\).
A 3-rd order approximation of the transport map is then built:
[18]:
order = 3
Tk_list = []
active_vars = []
c_basis_list = [S1D.HermiteProbabilistsPolynomial()]
c_orders_list = [0]
c_approx = FUNC.MonotonicLinearSpanApproximation(
c_basis_list, spantype='full', order_list=c_orders_list)
e_basis_list = [S1D.ConstantExtendedHermiteProbabilistsFunction()]
e_orders_list = [order]
e_approx = FUNC.MonotonicLinearSpanApproximation(
e_basis_list, spantype='full', order_list=e_orders_list)
Tk = FUNC.MonotonicIntegratedExponentialApproximation(c_approx, e_approx)
Tk_list.append( Tk )
active_vars.append( [0] )
T = MAPS.IntegratedExponentialTriangularTransportMap(active_vars, Tk_list)
2023-03-25 23:57:41 WARNING: TransportMaps: MonotonicLinearSpanApproximation DEPRECATED since v3.0. Use Functionals.PointwiseMonotoneLinearSpanTensorizedParametricFunctional instead.
2023-03-25 23:57:41 WARNING: TransportMaps: MonotonicLinearSpanApproximation DEPRECATED since v3.0. Use Functionals.PointwiseMonotoneLinearSpanTensorizedParametricFunctional instead.
2023-03-25 23:57:41 WARNING: TransportMaps: MonotonicIntegratedExponentialApproximation DEPRECATED since v3.0. Use Functionals.IntegratedExponentialParametricMonotoneFunctional instead
2023-03-25 23:57:41 WARNING: TransportMaps: IntegratedExponentialTriangularTransportMap DEPRECATED since v3.0. Use Maps.IntegratedExponentialParametricTriangularComponentwiseTransportMap instead
Alternatively one could use the default constructor:
[20]:
T = MAPS.assemble_IsotropicIntegratedExponentialTriangularTransportMap(
1, order, 'full')
2023-03-25 23:57:51 WARNING: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Be advised that in the current implementation of the "CommonBasis" componentwise maps, max_orders does not get updated when underlying directional orders change!!! (e.g. adaptivity)
We are then ready to set up the minimization problem
We need in particular to select \(\nu_\rho\) and to construct the distribution \(T_\sharp \nu_\rho\):
[21]:
rho = DIST.StandardNormalDistribution(1)
push_rho = DIST.PushForwardParametricTransportMapDistribution(T, rho)
pull_pi = DIST.PullBackParametricTransportMapDistribution(T, pi)
And we are ready to solve the KL-divergence minimization problem:
[22]:
qtype = 3 # Gauss quadrature
qparams = [20] # Quadrature order
reg = None # No regularization
tol = 1e-10 # Optimization tolerance
ders = 2 # Use gradient and Hessian
log = KL.minimize_kl_divergence(
rho, pull_pi, qtype=qtype, qparams=qparams, regularization=reg,
tol=tol, ders=ders)
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Gradient norm tolerance set to 1e-10
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Starting Newton-CG with user provided Hessian
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 1 - obj = 2.25900e+00 - jac 2-norm = 7.67e-01 - jac inf-norm = 4.97e-01
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 2 - obj = 1.83299e+00 - jac 2-norm = 9.23e-01 - jac inf-norm = 7.92e-01
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 3 - obj = 1.71258e+00 - jac 2-norm = 2.27e-01 - jac inf-norm = 1.50e-01
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 4 - obj = 1.59350e+00 - jac 2-norm = 2.76e-01 - jac inf-norm = 1.94e-01
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 5 - obj = 1.57875e+00 - jac 2-norm = 1.22e-01 - jac inf-norm = 8.71e-02
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 6 - obj = 1.55068e+00 - jac 2-norm = 1.08e-01 - jac inf-norm = 7.72e-02
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 7 - obj = 1.50143e+00 - jac 2-norm = 7.93e-02 - jac inf-norm = 5.74e-02
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 8 - obj = 1.43800e+00 - jac 2-norm = 2.33e-02 - jac inf-norm = 1.83e-02
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 9 - obj = 1.42938e+00 - jac 2-norm = 2.83e-03 - jac inf-norm = 2.01e-03
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 10 - obj = 1.42920e+00 - jac 2-norm = 3.85e-04 - jac inf-norm = 3.56e-04
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 11 - obj = 1.42920e+00 - jac 2-norm = 7.09e-06 - jac inf-norm = 7.06e-06
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 12 - obj = 1.42920e+00 - jac 2-norm = 7.79e-10 - jac inf-norm = 6.04e-10
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: Iteration 13 - obj = 1.42920e+00 - jac 2-norm = 7.79e-10 - jac inf-norm = 6.04e-10
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Optimization terminated successfully
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Function value: 1.429205e+00
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Jacobian 2-norm: 7.794199e-10 inf-norm: 6.036656e-10
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Number of iterations: 13
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. function evaluations: 14
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. Jacobian evaluations: 14
2023-03-25 23:58:21 INFO: TM.CommonBasisIntegratedExponentialParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. Hessian evaluations: 13
Let’s check the PDF approximation against the exact Gumbel distribution and the corresponding maps…
[23]:
plot_mapping(pi, Tstar, push_rho, T)
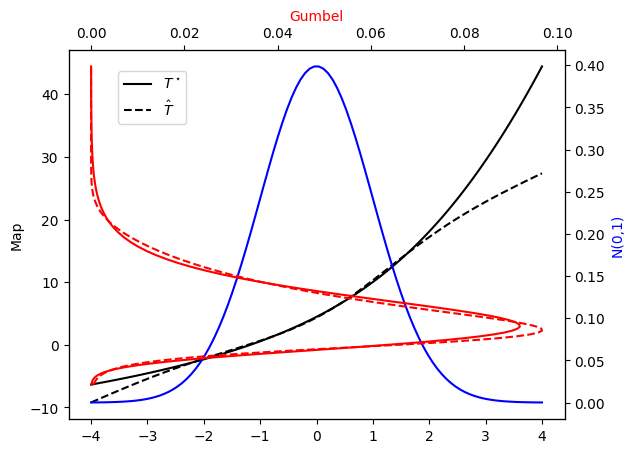
Integrated squared parametrization¶
This parameterization takes the form:
where \(c\) and \(h\) are themselves two parametric approximations. We use polynomial approximations for both of these functions, such that:
The advantage of using this parametrization, with Hermite polynomials for \(c({\bf a}_c,{\bf x})\) and constant extended Hermite functions (see SpectralToolbox documentation) for \(h({\bf a}_e,{\bf x})\), is that the integration can be performed analytically, rather than numerically. In general we will require the approximation \(c\) to be constant in \(x_d\) and this is achieved using a zero’s order approximation in the \(x_d\) dimension of \(c\).
We construct a 3-rd order approximation with the following code:
[39]:
order = 2
Tk_list = []
active_vars = []
c_basis_list = [S1D.HermiteProbabilistsPolynomial()]
c_orders_list = [0]
c_approx = FUNC.MonotonicLinearSpanApproximation(
c_basis_list, spantype='full', order_list=c_orders_list)
e_basis_list = [S1D.ConstantExtendedHermiteProbabilistsFunction()]
e_orders_list = [order]
e_approx = FUNC.MonotonicLinearSpanApproximation(
e_basis_list, spantype='full', order_list=e_orders_list)
Tk = FUNC.MonotonicIntegratedSquaredApproximation(c_approx, e_approx)
Tk_list.append( Tk )
active_vars.append( [0] )
T = MAPS.IntegratedSquaredTriangularTransportMap(active_vars, Tk_list)
2023-03-26 00:01:28 WARNING: TransportMaps: MonotonicLinearSpanApproximation DEPRECATED since v3.0. Use Functionals.PointwiseMonotoneLinearSpanTensorizedParametricFunctional instead.
2023-03-26 00:01:28 WARNING: TransportMaps: MonotonicLinearSpanApproximation DEPRECATED since v3.0. Use Functionals.PointwiseMonotoneLinearSpanTensorizedParametricFunctional instead.
2023-03-26 00:01:28 WARNING: TransportMaps: MonotonicIntegratedSquaredApproximation DEPRECATED since v3.0. IntegratedSquaredParametricMonotoneFunctional
2023-03-26 00:01:28 WARNING: TransportMaps: IntegratedSquaredTriangularTransportMap DEPRECATED since v3.0. Use Maps.IntegratedSquaredParametricTriangularComponentwiseTransportMap instead
Alternatively one could use the default constructor:
[40]:
T = MAPS.assemble_IsotropicIntegratedSquaredTriangularTransportMap(
1, order, 'full')
We are then ready to set up the minimization problem
We need in particular to chose \(\nu_\rho\) and to construct the distribution \(T_\sharp \nu_\rho\):
[41]:
rho = DIST.StandardNormalDistribution(1)
push_rho = DIST.PushForwardParametricTransportMapDistribution(T, rho)
pull_pi = DIST.PullBackParametricTransportMapDistribution(T, pi)
And we are ready to solve the KL-divergence minimization problem:
[42]:
qtype = 3 # Gauss quadrature
qparams = [15] # Quadrature order
reg = None # No regularization
tol = 1e-5 # Optimization tolerance
ders = 2 # Use gradient and Hessian
log = KL.minimize_kl_divergence(
rho, pull_pi, qtype=qtype, qparams=qparams, regularization=reg,
tol=tol, ders=ders)
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Gradient norm tolerance set to 1e-05
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Starting Newton-CG with user provided Hessian
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 1 - obj = 2.27979e+00 - jac 2-norm = 2.73e-01 - jac inf-norm = 2.51e-01
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 2 - obj = 1.61040e+00 - jac 2-norm = 7.50e-02 - jac inf-norm = 7.46e-02
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 3 - obj = 1.49385e+00 - jac 2-norm = 1.40e-02 - jac inf-norm = 1.30e-02
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 4 - obj = 1.48834e+00 - jac 2-norm = 8.31e-04 - jac inf-norm = 8.15e-04
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 5 - obj = 1.48832e+00 - jac 2-norm = 3.65e-06 - jac inf-norm = 2.93e-06
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 6 - obj = 1.48832e+00 - jac 2-norm = 3.81e-11 - jac inf-norm = 3.56e-11
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 7 - obj = 1.48832e+00 - jac 2-norm = 3.81e-11 - jac inf-norm = 3.56e-11
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Optimization terminated successfully
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Function value: 1.488320e+00
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Jacobian 2-norm: 3.811696e-11 inf-norm: 3.564250e-11
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Number of iterations: 7
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. function evaluations: 7
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. Jacobian evaluations: 7
2023-03-26 00:01:32 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. Hessian evaluations: 7
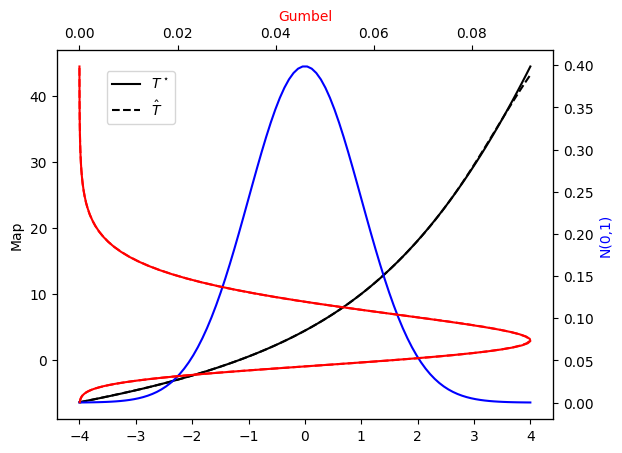
Let’s check the PDF approximation against the exact Gumbel distribution and the corresponding maps…
[43]:
plot_mapping(pi, Tstar, push_rho, T)
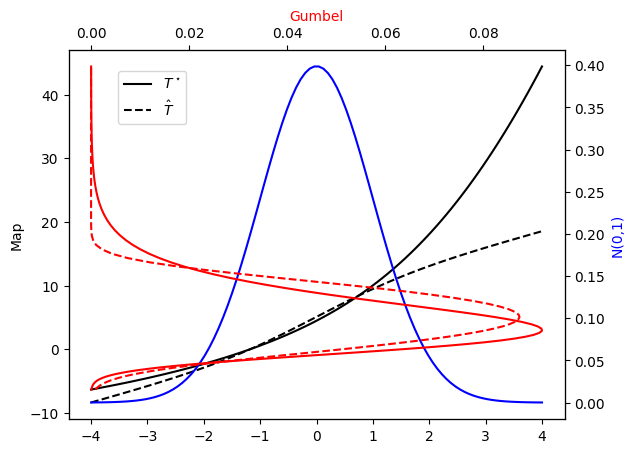
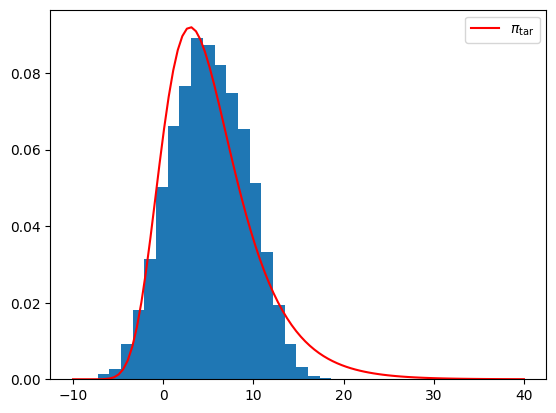
Sampling from the approximation¶
One of the strength of the transport map approach is that once the map \(\hat{T}\) is constructed, sampling from \(\hat{T}_\sharp \nu_\rho \approx \nu_\pi\) becomes a trivial and computationally cheap task. In fact,
This process is hidden to the user, who can directly handle the object \(\hat{T}_\sharp \nu_\rho\).
Monte-Carlo sampling¶
[44]:
M = 10000
samples = push_rho.rvs(M)
plt.figure()
plt.hist(samples,bins=20,density=True);
plt.plot(x, pi.pdf(x),'r',label=r'$\pi_{\rm tar}$');
plt.legend();
Gauss quadratures¶
[45]:
M = 5
(xq,wq) = push_rho.quadrature(qtype=3, qparams=[M])
plt.figure()
plt.plot(x, pi.pdf(x),'r',label=r'$\pi_{\rm tar}$');
plt.scatter(xq, np.zeros(len(xq)), s=100*wq+10.);
plt.legend();
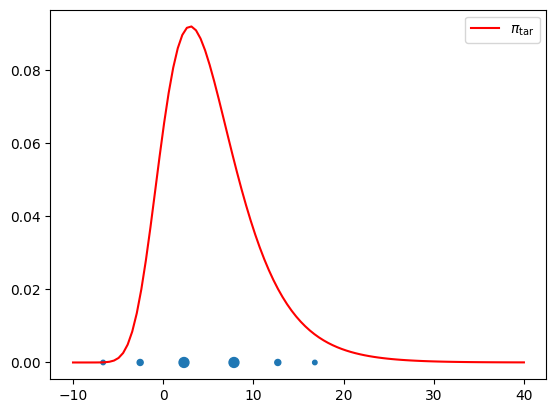
The approximation of higher order quadrature rules require the construction of higher order approximations. Let us try to construct a 10-th order quadrature rule using a 10-th order integrated exponential approximation.
[47]:
order = 10
T = MAPS.assemble_IsotropicIntegratedSquaredTriangularTransportMap(1, order, 'full')
rho = DIST.StandardNormalDistribution(1)
push_rho = DIST.PushForwardParametricTransportMapDistribution(T, rho)
pull_pi = DIST.PullBackParametricTransportMapDistribution(T, pi)
qtype = 3 # Gauss quadrature
qparams = [20] # Quadrature order
reg = None # No regularization
tol = 1e-10 # Optimization tolerance
ders = 2 # Use gradient and Hessian
log = KL.minimize_kl_divergence(
rho, pull_pi, qtype=qtype, qparams=qparams, regularization=reg,
tol=tol, ders=ders)
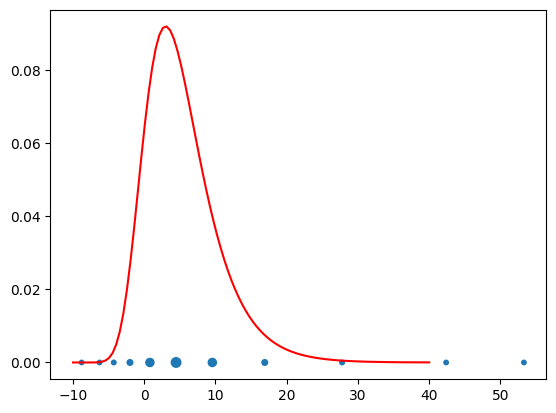
plot_mapping(pi, Tstar, push_rho, T)
M = 10
(xq,wq) = push_rho.quadrature(qtype=3, qparams=[M])
plt.figure()
plt.plot(x, pi.pdf(x),'r',label=r'$\pi_{\rm tar}$');
plt.scatter(xq, np.zeros(len(xq)), s=100*wq+10.);
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Gradient norm tolerance set to 1e-10
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Starting Newton-CG with user provided Hessian
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 1 - obj = 2.24554e+00 - jac 2-norm = 6.14e-01 - jac inf-norm = 4.04e-01
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 2 - obj = 1.86993e+00 - jac 2-norm = 1.95e-01 - jac inf-norm = 1.57e-01
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 3 - obj = 1.46980e+00 - jac 2-norm = 5.73e-02 - jac inf-norm = 4.05e-02
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 4 - obj = 1.42101e+00 - jac 2-norm = 7.41e-03 - jac inf-norm = 5.28e-03
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 5 - obj = 1.41906e+00 - jac 2-norm = 5.61e-04 - jac inf-norm = 3.50e-04
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 6 - obj = 1.41895e+00 - jac 2-norm = 2.55e-05 - jac inf-norm = 1.25e-05
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 7 - obj = 1.41895e+00 - jac 2-norm = 2.71e-06 - jac inf-norm = 2.05e-06
2023-03-26 00:02:27 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 8 - obj = 1.41895e+00 - jac 2-norm = 2.26e-06 - jac inf-norm = 1.59e-06
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 9 - obj = 1.41895e+00 - jac 2-norm = 2.20e-06 - jac inf-norm = 2.05e-06
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 10 - obj = 1.41895e+00 - jac 2-norm = 4.67e-06 - jac inf-norm = 2.49e-06
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 11 - obj = 1.41895e+00 - jac 2-norm = 1.16e-06 - jac inf-norm = 9.15e-07
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 12 - obj = 1.41895e+00 - jac 2-norm = 4.24e-06 - jac inf-norm = 2.25e-06
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 13 - obj = 1.41895e+00 - jac 2-norm = 1.02e-06 - jac inf-norm = 8.02e-07
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: Iteration 14 - obj = 1.41895e+00 - jac 2-norm = 1.02e-06 - jac inf-norm = 8.02e-07
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Optimization terminated successfully
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Function value: 1.418950e+00
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Jacobian 2-norm: 1.021135e-06 inf-norm: 8.023320e-07
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: Number of iterations: 14
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. function evaluations: 14
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. Jacobian evaluations: 14
2023-03-26 00:02:28 INFO: TM.IntegratedSquaredParametricTriangularComponentwiseTransportMap: minimize_kl_divergence: N. Hessian evaluations: 14
Accuracy diagnostics¶
The estimation of the accuracy of the approximation \(\hat{T}_\sharp \nu_\rho\) of \(\nu_\pi\) is a fundamental feature deriving from the fact that we are not only computing a density approximation, but also a transport attaining this approximation.
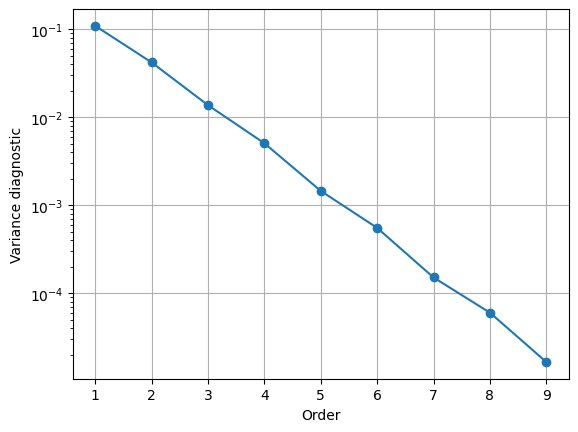
Variance diagnostic¶
As shown in [TM1], as \(\mathcal{D}_{\rm KL}\left(T_\sharp \nu_\rho \middle\Vert \nu_\pi\right) \rightarrow 0\) (i.e. as \(T\rightarrow T^\star\)), the following hold:
This diagnostic can be easily computed using the following code:
[48]:
import TransportMaps.Diagnostics as DIAG
pull_pi = DIST.PullBackTransportMapDistribution(T, pi)
var = DIAG.variance_approx_kl(rho, pull_pi, qtype=3, qparams=[20])
print("Variance diagnostic: %e" % var)
Variance diagnostic: 8.087255e-06
Let us then look at how this quantity behaves as we increase the order of the approximation.
[51]:
def plot_var_diag():
var_list = []
ord_list = list(range(1,10))
for order in ord_list:
T = MAPS.assemble_IsotropicIntegratedSquaredTriangularTransportMap(
1, order, 'full')
push_rho = DIST.PushForwardParametricTransportMapDistribution(T, rho)
pull_pi = DIST.PullBackParametricTransportMapDistribution(T, pi)
log = KL.minimize_kl_divergence(
rho, pull_pi, qtype=qtype, qparams=qparams, regularization=reg,
tol=tol, ders=ders)
pull_pi = DIST.PullBackTransportMapDistribution(T, pi)
v = DIAG.variance_approx_kl(rho, pull_pi, qtype=3, qparams=[20])
var_list.append(v)
plt.figure()
plt.semilogy(ord_list, var_list, '-o');
plt.grid();
plt.xlabel('Order');
plt.ylabel('Variance diagnostic');
[52]:
TM.setLogLevel(logging.WARNING)
plot_var_diag()